Das Spiel zur Illustration bestärkenden Lernens lässt sich gut einleiten, in dem Sie die SuS zunächst fragen, wie sie bei Videospielen lernen, um die verschiedenen Levels zu bestehen. Die SuS erzählen von ihren Lernstrategien, die wahrscheinlich darin bestehen, dass sie Aktionen, die zu Erfolg führen vermehrt ausführen und solche die zu Bestrafungen führen vermeiden. Diese Lernstrategie benutzt der Mensch auch im Alltag: Strafen in der Schule, gute Noten bei einem Test, Strafzettel im Straßenverkehr, Punkteführerschein usw.
Daraufhin erklären Sie, dass auch KI-Systeme auf diese Art und Weise autonom lernen und dies in vielen Videospielen genutzt wird. Auch werden viele KI-Systeme zuerst an Spielen getestet, da diese ein überschaubares Regelwerk besitzen und weniger komplex sind als die Realität. Sehr bekannt wurde KI durch seinen Sieg gegen den Schachweltmeister Kasparov im Jahre 1997 (Deep Blue) und gegen den Weltmeister im Go-Spiel im Jahre 2016 (IBM Watson).
Im Kleinen lässt sich das am Bauernschach bzw. dem Spiel „Schlag das Krokodil“ nachvollziehen. Die Spielregeln stammen vom richtigen Schachspiel: Die Bauernfigur kann geradeaus auf das vor ihr liegende Feld ziehen, wenn dieses frei ist, oder diagonal nach vorne, um einen gegnerischen Bauern zu schlagen. Gewonnen hat die/der SpielerIn, die/der es schafft, die eigene Spielfigur an das andere Ende des Spielfeldes zu führen, oder alle gegnerischen Figuren geschlagen hat oder erreicht, dass der Gegner in der nächsten Runde keinen Spielzug mehr ausführen kann.
Demonstrieren Sie zunächst die Funktionsweise der Website https://www.stefanseegerer.de/schlag-das-krokodil und erklären Sie die Spielregeln. Darüber hinaus ist es wichtig, dass die SuS die Bedeutung der farbigen Punkte verstehen (entsprechen der gleichfarbigen Aktion) und sehen, dass diese Punkte entfernt oder hinzugefügt werden können.
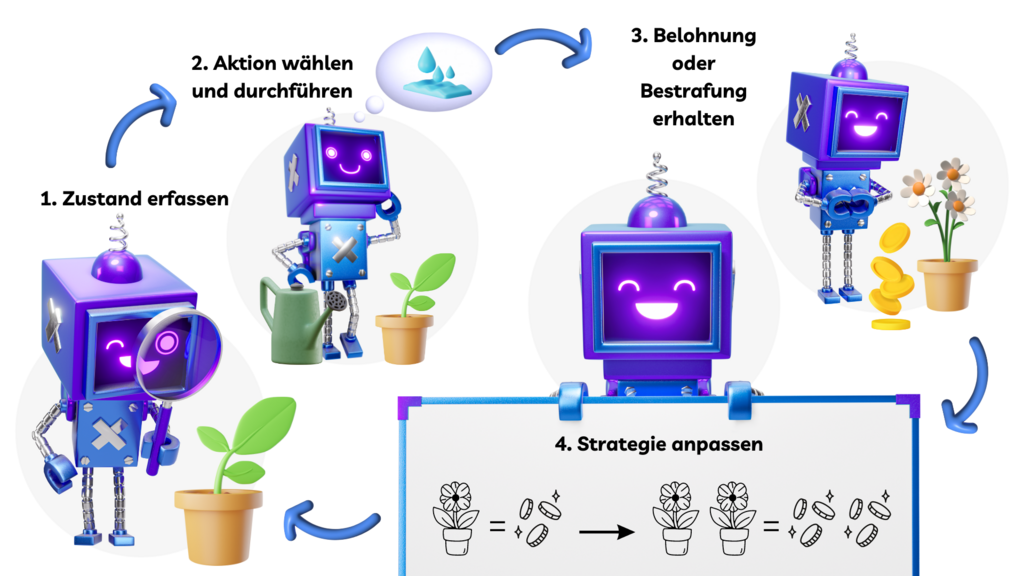
Bevor eine neue Runde gespielt wird, passt der Computer seine Strategie wie folgt an:
Computer hat gewonnen: Ein Token in der Farbe des letzten, siegbringenden Spielzugs wird zusätzlich auf das Feld dieses Spielzugs gelegt.
Mensch hat gewonnen: Das Token, das den letzten Zug der Computer-Spielerin bzw. des Computer-Spielers bestimmt hat, wird entfernt.
Lassen Sie die SuS nun einige Runden allein spielen. Ziel ist es, so oft wie möglich zu gewinnen, bevor die KI nicht mehr geschlagen werden kann. Dies scheint eine einfache Aufgabe zu sein, aber bald werden die SuS erkennen, dass sie ein gutes Verständnis des Innenlebens benötigen, um über 10 oder sogar über 20 Siege zu erzielen. Achtung, wenn die Seite neu geladen wird, werden auch die Gewinne zurückgesetzt!
Reflexion: Die SuS werden erkennen, dass sie zu Beginn noch oft gewinnen. Nach einigen Runden wird der Computer jedoch immer besser, da durch bestärkendes Lernen nur die Spielzüge übrigbleiben, die zu einem Gewinn führen. Schlussendlich werden die SuS nicht mehr gegen den Computer gewinnen können. Sie sollten erkennen, dass sie gezielt Züge machen müssen, die sie zuvor noch nicht verwendet haben, um die KI in unbekanntes Gebiet zu „zwingen“. Es ist auch gut ersichtlich, dass die Anzahl der möglichen Zustände mit der Anzahl der verfügbaren Aktionen recht schnell zunimmt. Man kann sich leicht vorstellen, dass es auf einem größeren Brett (wie z.B. einem Schachbrett) so viele mögliche Zustände gibt, dass es nicht möglich ist, eine KI von Hand zu trainieren oder sogar generell alle möglichen Zustände einzubeziehen. Wichtig ist auch die Qualität des menschlichen Spielers: Verliert die Maschine nicht, entwickelt sie sich auch nicht weiter. Verliert sie aber, wird jeweils der letzte Zug, der in direkter Folge zum Verlieren geführt hat, eliminiert, d. h. aus der Ergebnisübersicht gestrichen. Dies stellt eine negative Bestärkung (Bestärkung erfolgreicher Handlung findet hier nicht statt) dar, da der Zug in Zukunft mit Sicherheit nicht mehr angewendet wird. Die Maschine lernt auf diese Weise besser zu spielen.
Zur Vertiefung siehe auch https://computingeducation.de/proj-schlag-das-kroko/.